레이어별 임베딩: Gemma 4 소형 모델의 마법에 대한 간단한 설명
핵심 요약
Gemma 4 소형 모델에서 임베딩 파라미터가 왜 효과적인 파라미터 수에 포함되지 않는지, 레이어별 임베딩 기술을 통해 설명함.
- 레이어별 임베딩 — 토큰 임베딩을 단일 행렬이 아닌 각 레이어별로 분산 배치하여 모델의 문맥 이해도를 높임.
- 효과적 파라미터 — 임베딩 파라미터는 고정된 룩업 테이블로 작동하므로 실제 연산 시 전체 파라미터 수에서 제외됨.
- 추론 최적화 — 임베딩을 CPU로 오프로드하여 VRAM 사용량을 획기적으로 줄이고 효율적인 추론이 가능함.
- 기술적 오해 — 기존 트랜스포머 교육 자료가 임베딩을 행렬 곱셈으로 설명하는 방식의 비효율성을 지적함.
많은 분들이 제 최근 게시물 "TurboQuant의 핵심 아이디어에 대한 간단한 설명"을 좋아해 주셨던 것 같습니다. 저는 블로거와는 거리가 멀고 보통 가용한 모든 시간을 Heretic 개발에 투자하는 편이지만, 최근 많은 혼란을 야기하고 있는 정말 멋진 새로운 개발 사항이 있어서 또 다른 빠른 설명글을 작성하기로 했습니다.
여러분도 눈치채셨겠지만, 아주 새로운 Gemma 4 모델 제품군에는 두 가지 소형 모델이 포함되어 있습니다: gemma-4-E2B와 gemma-4-E4B.
네, "A"가 아니라 "E"입니다.
이 모델들은 Mixture-of-Experts(MoE) 모델도 아니고, 전통적인 의미의 밀집(dense) 모델도 아닙니다. 이들은 완전히 다른 무언가이며, 추론을 위한 흥미로운 새로운 성능 트레이드오프를 가능하게 합니다.
무슨 일이 일어나고 있는 걸까요?
이 모델들이 어떻게 작동하고 왜 그렇게 멋진지 이해하기 위해, Mixture-of-Experts(MoE) 모델이 무엇인지 빠르게 복습해 보겠습니다:
gemma-4-26B-A4B는 MoE 모델의 예시입니다. 이 모델은 252억 개의 파라미터를 가지고 있습니다(모델 이름에서는 26B로 반올림됨). 아시다시피 트랜스포머 언어 모델은 레이어로 구성되어 있으며, 각 레이어에는 레이어 스택을 통과하는 잔차 벡터를 처리하는 MLP(Multi-Layer Perceptron) 구성 요소가 포함되어 있습니다. MoE 모델에서 그 MLP는 학습 중에 전문화되는 법을 배우는 하위 네트워크인 "전문가(experts)"로 나뉩니다. 라우팅 네트워크는 각 토큰마다 어떤 전문가가 가장 적합한지 결정하며, 해당 토큰을 처리할 때는 그 전문가 네트워크들만 실제로 사용됩니다.
즉, MoE 모델은 많은 파라미터를 가지고 있지만, 특정 위치에서 다음 토큰을 예측하는 데 필요한 파라미터는 그중 일부에 불과합니다. 이것이 모델 이름의 의미입니다: gemma-4-26B-A4B는 총 260억(실제로는 252억) 개의 파라미터를 가지고 있지만, 단일 추론 단계에서 활성화되는 파라미터는 40억(실제로는 38억) 개뿐입니다.
좋은 소식은 밀집 26B 모델보다 훨씬 빠르게 추론할 수 있다는 것입니다. 계산에 38억 개의 파라미터만 관여하기 때문입니다. 나쁜 소식은 여전히 252억 개의 파라미터를 모두 VRAM(또는 빠른 RAM)에 로드할 수 있어야 한다는 것입니다. 그렇지 않으면 토큰마다 어떤 파라미터가 필요할지 미리 알 수 없고 활성 전문가가 토큰마다 다를 수 있기 때문에 성능이 급락하게 됩니다.
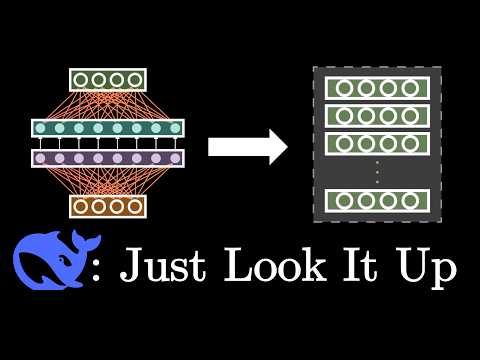
이제 gemma-4-E2B는 매우 다른 짐승입니다: 51억 개의 파라미터를 가지고 있지만, 그중 28억 개가 임베딩 파라미터입니다. 구글은 이 파라미터들이 "계산되지 않는다"고 주장하며, 따라서 실제로는 23억 개의 효과적인 파라미터만 있다고 말합니다. 이것이 "E2B" 부분이 의미하는 바입니다.
뭐라구요? 왜 임베딩 파라미터는 계산되지 않나요?
언어 모델에 대한 기본적인 소개를 읽거나 보셨다면 임베딩이 무엇인지 아마 아실 겁니다: 임베딩은 어휘의 각 토큰과 연관된 고차원 벡터입니다. 직관적으로 말하면, 임베딩 공간에서 방향-크기 조합으로 인코딩된 토큰의 "본질"을 포착합니다.
임베딩은 정적이며 위치 독립적입니다. 특정 토큰과 연관된 임베딩 벡터는 입력의 어디에 나타나든, 주변에 어떤 토큰이 있든 항상 동일합니다. 수학적 공식에서 임베딩은 종종 행렬로 표현되며, 이를 원-핫 인코딩된 토큰 행렬과 곱하여 해당 토큰에 대한 임베딩 벡터 행렬을 얻을 수 있습니다.
소형 Gemma 4 모델은 **레이어별 임베딩(Per-Layer Embeddings, PLE)**을 사용합니다: 처리 시작 시 토크나이저 직후에 적용되는 단일 대형 임베딩 행렬 대신, 각 레이어에 대한 추가적인(더 작은) 임베딩 행렬이 존재합니다. 학습을 통해 이들은 각 레이어의 의미론적 전문화에 맞춰 토큰을 재맥락화할 수 있는 전문 지식을 습득하며, 이는 처리 품질을 크게 향상시킵니다. 레이어 기반 임베딩 벡터는 일련의 연산을 통해 잔차와 결합되어 국소적으로 관련된 정보를 추가합니다.